Demystifying Dependency Injection and Inversion of Control: Building Maintainable and Testable Code
Discover the power of Dependency Injection and Inversion of Control. Learn how these essential principles elevate code quality, making it maintainable and testable.
Introduction
Two very common principles you come across quite often in software development are dependency injection and inversion of control. It took me a while to grasp the concepts of dependency injection and inversion of control, their true meanings, and the issues they address.
Especially in the beginning, I often found myself using these terms synonymously. I also assumed that both are two different terms for the same thing.
However, eventually it clicked and I understood that those two principles are in fact two different things. It is just that they are used together quite often. In this article I try to explore this.
A basic example
Disclaimer: All the sample code in this article is written in C# since that is the programming language I’m currently most comfortable with. I've aimed to keep the examples simple, so even if C# isn't your primary language, you should be able to follow along and apply these concepts to other programming languages.
Let’s look at the following example: Let’s imagine an application with a simple login page.
Using the model view view model - mvvm - pattern, we want to implement a view model to add the login functionality to the page:
public class LoginPageViewModel
{
Task LoginAsync(string username, string password)
{
// (...)
}
}
If you aren’t familiar with the C# programming language: Don’t get confused by the method nameLoginAsync(...). It is just a language convention in C# to add theAsynckeyword to any method name that does some kind of asynchronous operation.
Inside the LoginAsync(...) method we want to authenticate the user using it’s username and password.
Let’s assume authenticating the user involves sending an http request. The simplest approach here would be to create an http client in the constructor and then use it inside the Login method to send the login request:
public class LoginPageViewModel
{
private readonly HttpClient _httpClient;
public LoginPageViewModel()
{
_httpClient = new HttpClient("https://your_web_api");
}
Task LoginAsync(string username, string password)
{
await _httpClient.Post("Login", username, password);
}
}
Now, first of all, this works totally fine. And I would like to use this opportunity to point out that this might be totally fine for your application. Please do not assume that you have to use the principles we explore in this article all the time. As you will see, even though they produce code that is better maintainable and testable, they also add a fair bit of complexity. So you should always balance on whether it is actually worth to add this additional amount complexity and if the benefits you get outweigh the added complexity.
But let’s look at the problems that might occur with this implementation. By directly creating the HttpClient inside the view model class, the LoginPageViewModel now has a direct dependency on the HttpClient class.
Also, the LoginPageViewModel has to know how to set up the http client that is necessary to send the login request, e.g. it has to know the url of the web api and if any additional headers are needed. If you want to target a different url (e.g. change between a production and a staging environment), you would have to adjust the LoginPageViewModel.
Let’s see how dependency injection can help to improve the situation here.
Using dependency injection
As stated above, our goal at this point is to avoid that the LoginPageViewModel has to have the knowledge on how to set up the HttpClient.
We can achieve this by not instantiating the HttpClient inside the view model, but by injecting it as a dependency via the constructor:
public class LoginPageViewModel
{
private readonly HttpClient httpClient;
public LoginPageViewModel(HttpClient httpClient)
{
httpClient = httpClient;
}
void Login(string username, string password)
{
httpClient.Post(...)
}
}
At a first glance, this may doesn’t seem to look like a big change at all. But as the LoginPageViewModel now get’s a ready-to-use http client injected via its constructor, it does not have to know anything about how to setup the http client, e.g. the target url or any special headers that maybe have to be added to communicate with the web api.
So using constructor injection helps you to take responsibility from a class and thus helps you to respect the Single Responsibility Principle.
Now let’s explore how we can improve the code a bit further.
Even though the view model now does not have to know how to create the http client, it still knows that the login requires sending an http request. I would consider this a detail the view model shouldn’t have to know about. Or in other words, the LoginPageViewModel should not be concerned about how the login technically works. This is where the Separation of Concerns principle can help.
Wrapping the login logic in a LoginService
First of all, let’s create a new class called LoginService:
public class LoginService : ILoginService
{
// (...)
public LoginPageViewModel(HttpClient httpClient)
{
httpClient = httpClient;
}
public Task LoginAsync(string username, string password)
{
// Doing the login here
}
}
As you can see, this class gets injected inject an HttpClient. It’s purpose is to encapsulate the login functionality.
Instead of using the HttpClient inside the LoginPageViewModel directly, we now inject the LoginService as a dependency:
public class LoginPageViewModel
{
private readonly LoginService _loginService;
public LoginPageViewModel(LoginService loginService)
{
_loginService = loginService;
}
Task LoginAsync(string username, string password)
{
await loginService.Login(username, password);
}
}
As you can see, the LoginPageViewModel now does not know any details on how the login actually works. It simply calls into the LoginService to do it. By encapsulating how the login actually works inside the LoginService, we are able to keep this implementation detail from the LoginPageViewModel.
So again, another improvement. Now let’s look at the last optimisation we want to do. There is still one thing that could be improved here: The LoginPageViewModel currently has a dependency on a concrete implementation of the LoginService.

What if we want to change the LoginService implementation that is used inside the LoginPageViewModel? We might want to inject a mock variant of the LoginService into the LoginPageViewModel during unit tests. It would require us to adjust the view model itself, which is not optimal.
As long as the LoginPageViewModel has a dependency on a concrete LoginService implementation, it is pretty hard to swap it against a mock variant, e.g. during a unit test (at least with a statically typed language like C#).
Introducing an ILoginService interface
Introducing an interface for the LoginService enables us to resolve this problem:
public interface ILoginService
{
Task LoginAsync(string username, string password);
}
This is also revered to as the “inversion of control” principle, since by introducing an interface, we invert the dependency between the LoginViewModel and the LoginService:
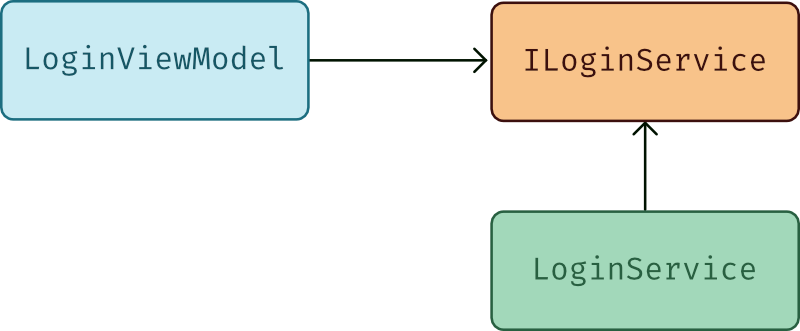
The LoginService we built earlier, implements this interface:
public class LoginService : ILoginService
{
public Task LoginAsync(string username, string password)
{
// Doing the login here
}
}
Instead of using the LoginService in the LoginPageViewModel directly, we now inject an ILoginService into it:
public class LoginPageViewModel
{
private readonly ILoginService loginService;
public LoginPageViewModel(ILoginService loginService)
{
this.loginService = loginService;
}
void Login(string username, string password)
{
// (...)
loginService.Login(username, password);
}
}
Conclusion
In this article, I explained how both the “dependency injection” principle and the “inversion of control” principle work and how they distinguish each other.
With a given sample app, I demonstrated which advantages you get when you use them in tandem and how it improves the maintainability as well as the testability of your code.
Thanks for reading this article! If you liked it and it helped you in any way getting a grasp on a new topic, the best way to support this blog is just by sharing it with others. However, if you would like to support me and my work more directly you can just buy me a cup of coffee (which as we know will eventually be converted into code):